|
|
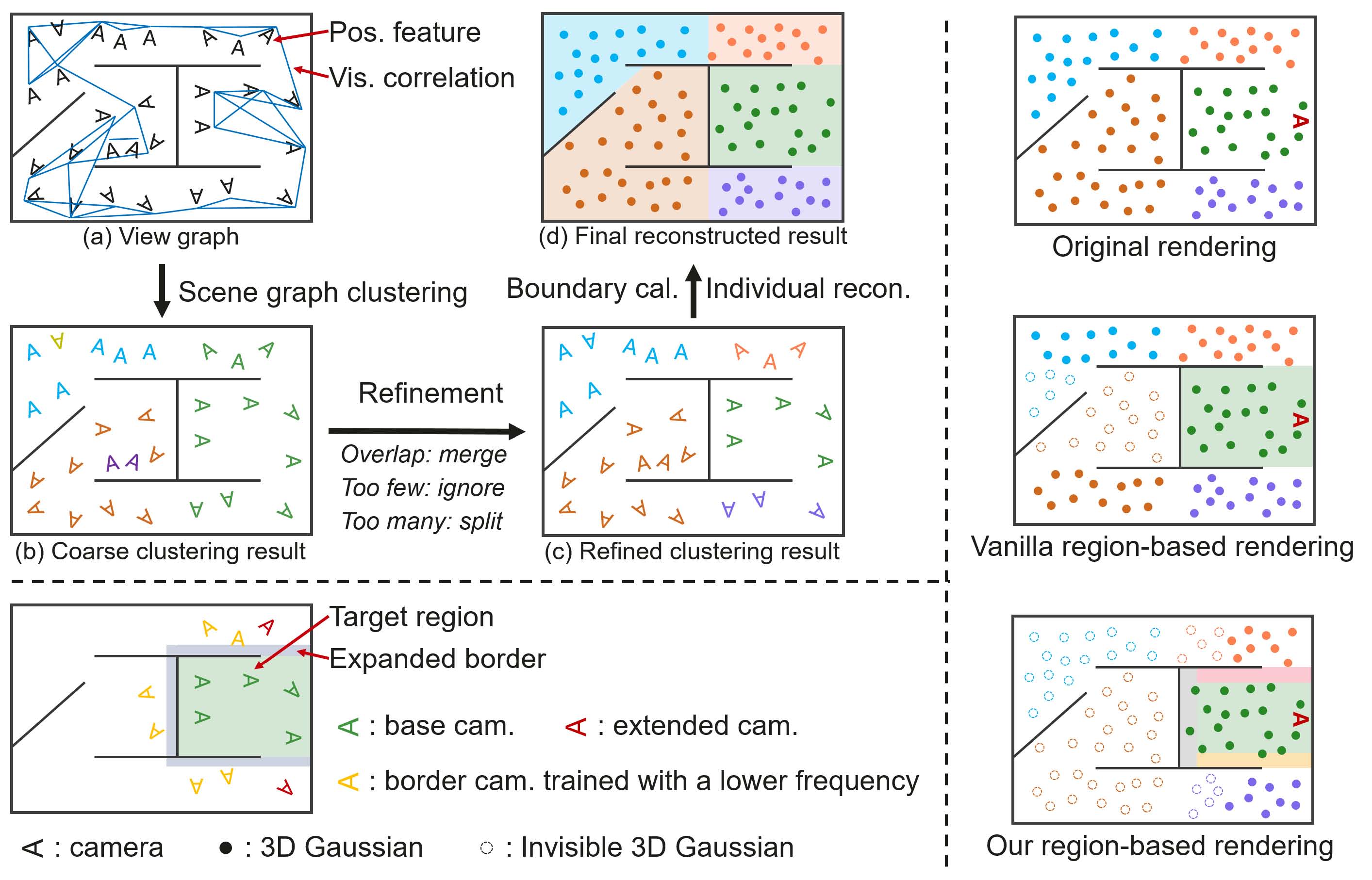
OccluGaussian: Occlusion-Aware Gaussian Splatting for Large Scene Reconstruction and Rendering
ICCV, 2025
项目页面
/
arXiv
一种通过 occlusion-aware 相机聚类和基于区域的高斯剔除来加速和增强大规模3D场景重建的方法。
|
|
|
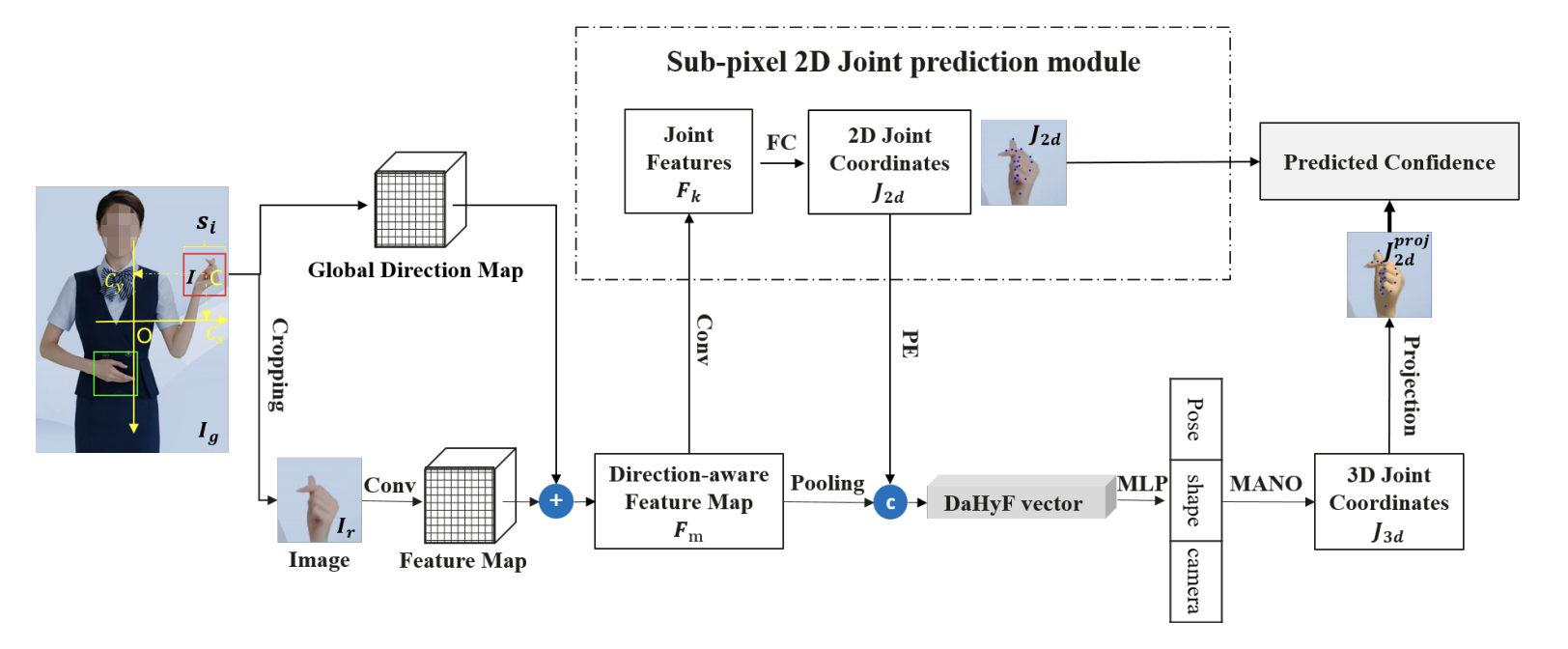
Direction-Aware Hybrid Representation Learning for 3D Hand Pose and Shape Estimation
CVPRW, 2025,
在HO3Dv2/v3排行榜的PA-MPJPE指标中获得第一名
项目页面
/
arXiv
一种3D手部姿态/形状估计方法,将隐式图像/显式2D关节特征与像素方向信息融合,通过基于置信度的预测减少运动抖动。
|
|
|
SpecTRe-GS: Modeling Highly Specular Surfaces with Reflected Nearby Objects by Tracing Rays in 3D Gaussian Splatting
CVPR, 2025,
Highlight
项目页面
/
arXiv
一种通过在3D高斯溅射中追踪光线来增强3DGS以处理高光反射的方法,分离高光/粗糙表面类型并优化几何结构,以提高渲染精度并支持场景编辑。
|
|
|
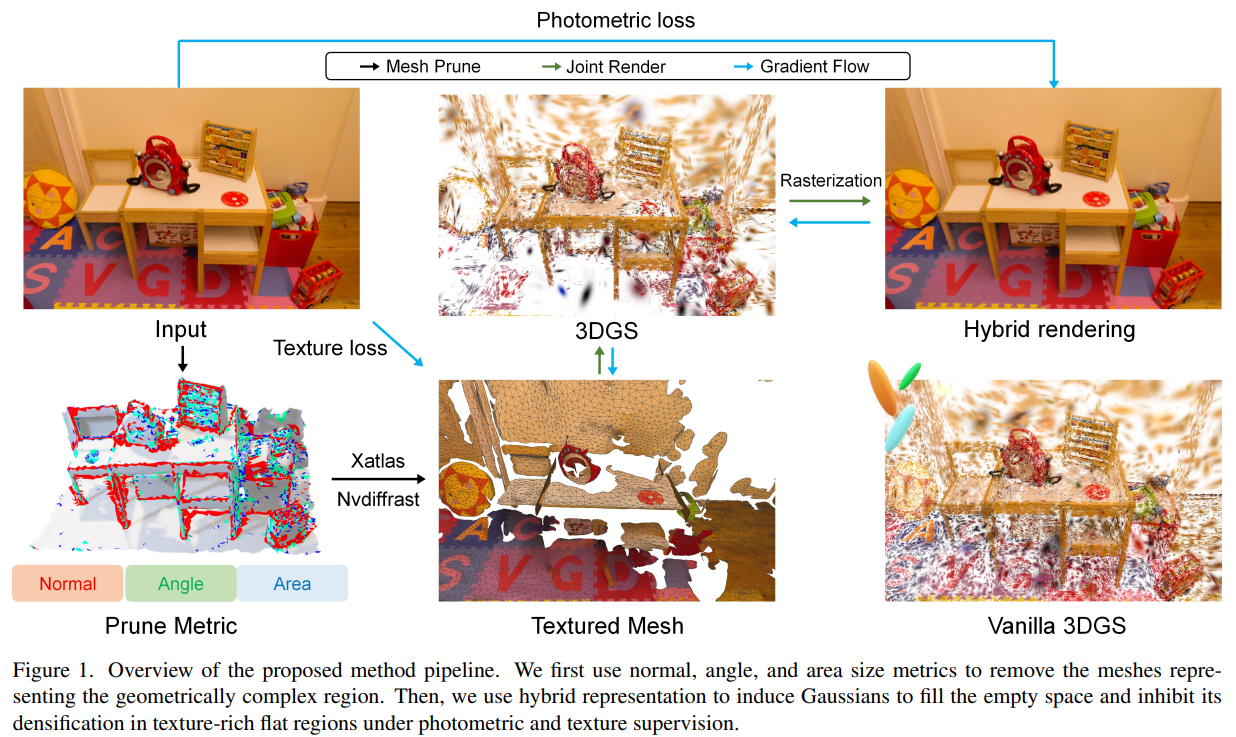
Hybrid Mesh-Gaussian Representation for Efficient Indoor Scene Reconstruction
IJCAI, 2025
项目页面
/
arXiv
一种混合3DGS和带纹理网格的表示方法,其中网格处理富含纹理的平坦区域,高斯处理复杂几何结构,通过预热策略和透射率感知监督的联合训练进行优化,以更少的高斯实现相当的渲染质量和更高的FPS。
|
|
|
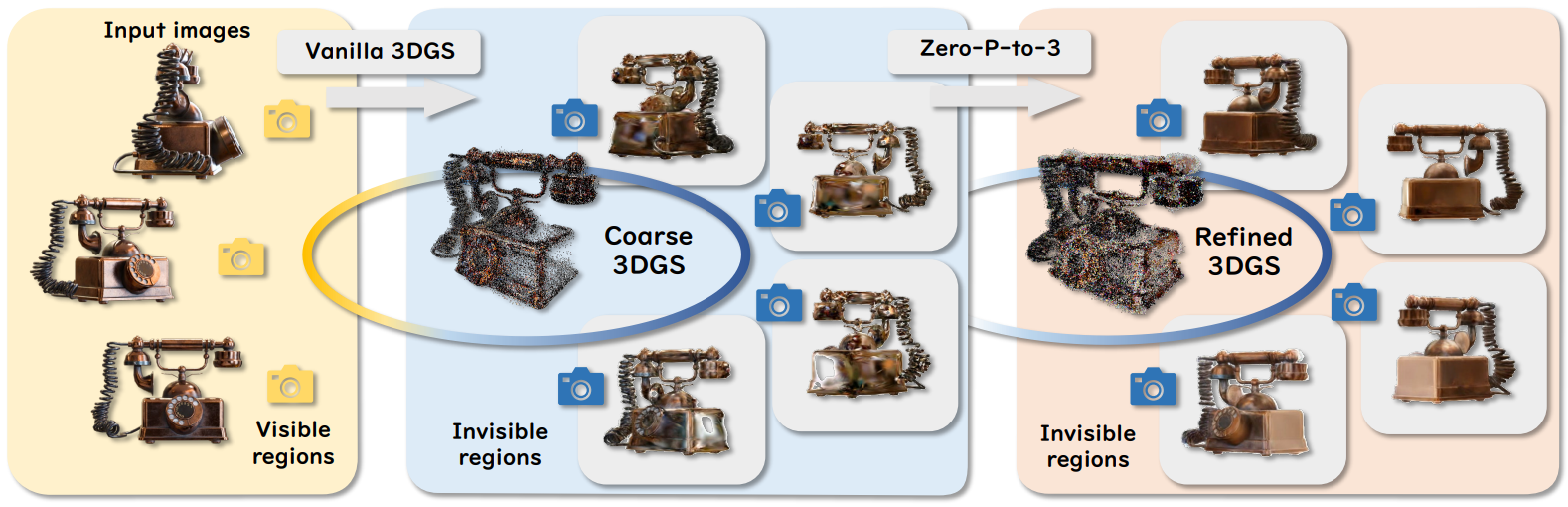
Zero-P-to-3: Zero-Shot Partial-View Images to 3D Object
arXiv, 2025
项目页面
/
arXiv
部分观察中的生成式3D重建受到有限视场和生成不一致的阻碍,而无需训练的Zero-P-to-3通过基于融合的DDIM采样和迭代优化整合局部密集观察和多源先验,特别是在不可见区域优于现有技术。
|
|
|
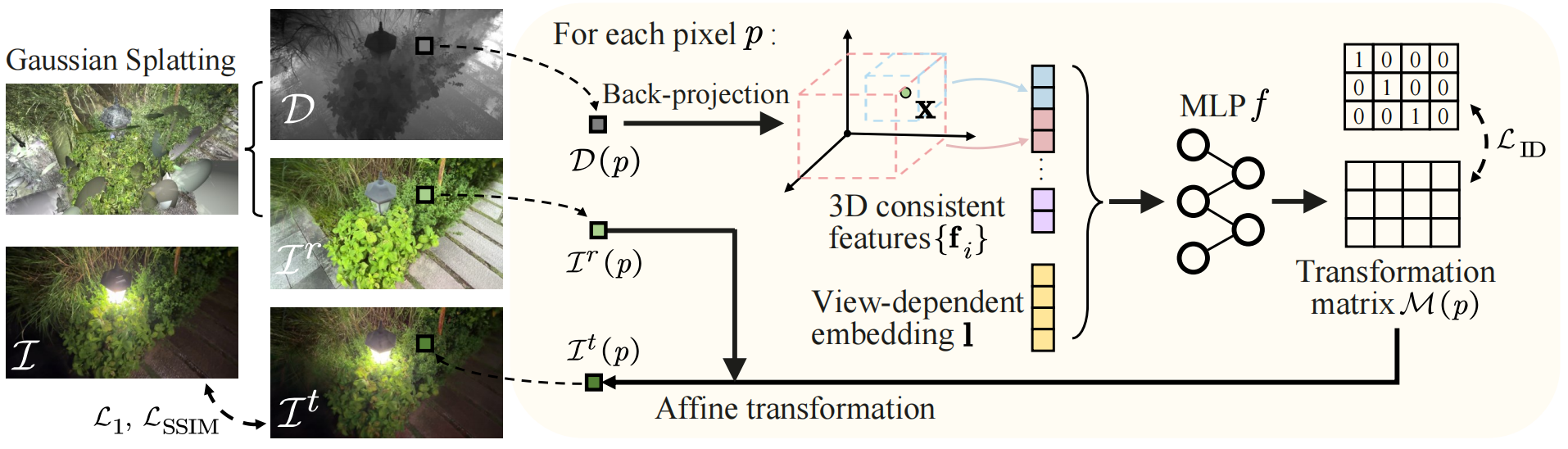
Decoupling Appearance Variations with 3D Consistent Features in Gaussian Splatting
AAAI, 2025
项目页面
/
arXiv
一种以即插即用和高效的方式解耦外观变化的方法。
|
|
|
Vastgaussian: Vast 3d gaussians for large scene reconstruction
CVPR, 2024
项目页面
/
arXiv
一种用于大场景重建的方法,支持快速优化和高保真实时渲染。
|
|
|
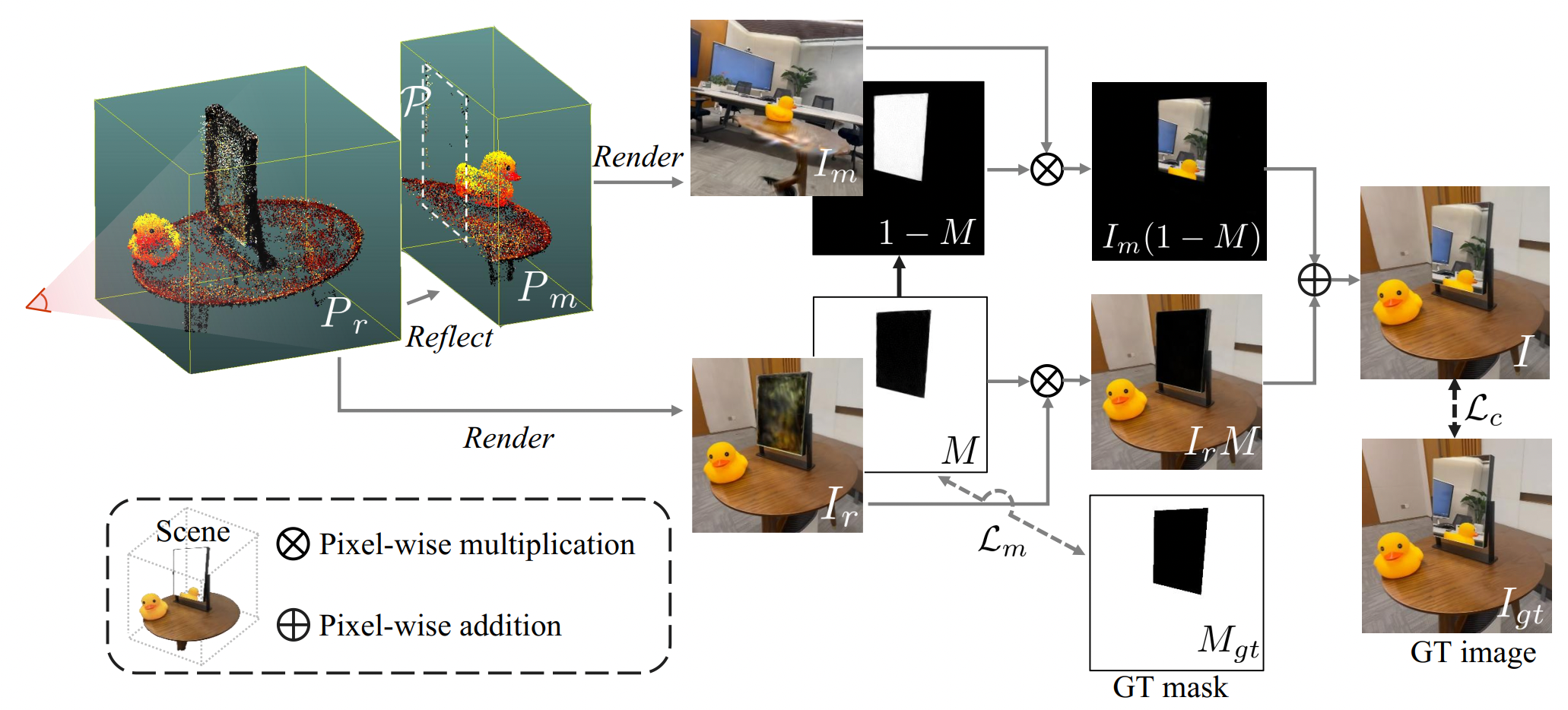
Mirrorgaussian: Reflecting 3d gaussians for reconstructing mirror reflections
ECCV, 2024
项目页面
/
arXiv
MirrorGaussian在带镜子的场景中实现高质量实时渲染,支持添加新镜子和物体等场景编辑功能。
|
|
|
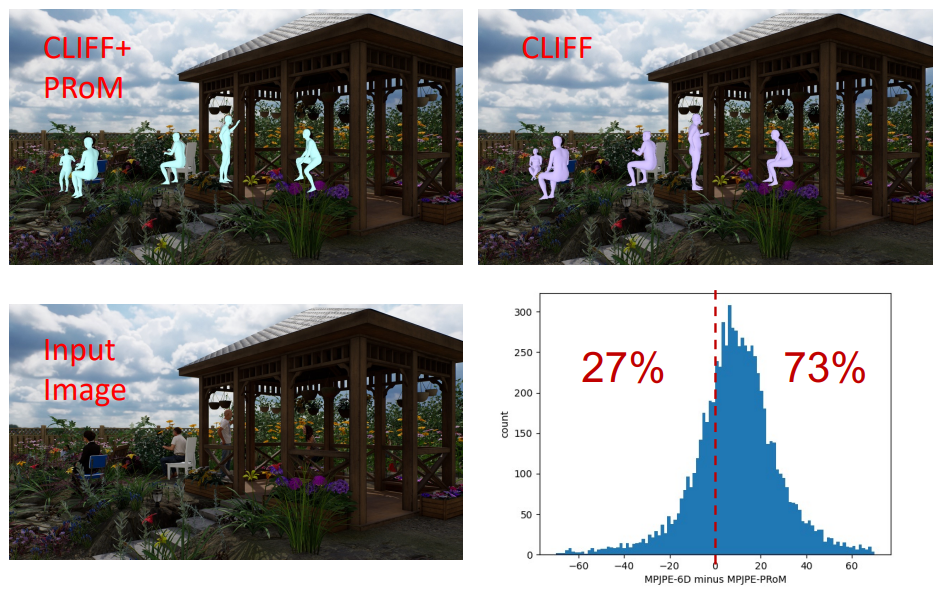
LEARNING UNORTHOGONALIZED MATRICES FOR ROTATION ESTIMATION
arXiv, 2023
项目页面
/
arXiv
3D旋转估计依赖于旋转表示,这项工作揭示常见的正交化过程会降低训练效率,因此主张学习非正交化伪旋转矩阵(PRoM),其能更快收敛到更好的解,并在大规模基准测试的人体姿态估计中取得最先进的结果。
|